Fitting
from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from example_models import get_linear_chain_2v
from mxlpy import Simulator, fit, make_protocol, plot
Fitting¶
Almost every model at some point needs to be fitted to experimental data to be validated.
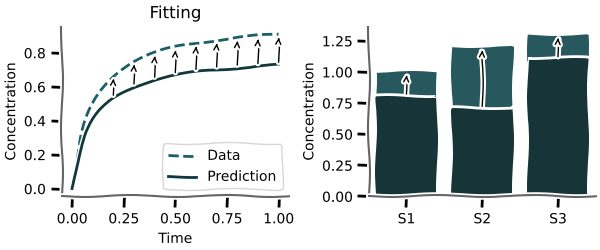
mxlpy offers highly customisable local and global routines for fitting either time series or steady-states.
The entire set of currently supported routines is
Single model, single data
steady_statetime_courseprotocol_time_course
Single model, single data, multiple initial guesses (a.k.a. multi-start optimisation)
group_steady_stategroup_time_coursegroup_protocol_time_course
Multiple model, single data
ensemble_steady_stateensemble_time_courseensemble_protocol_time_course
A carousel is a special case of an ensemble, where the general structure (e.g. stoichiometries) is the same, while the reactions kinetics can vary
carousel_steady_statecarousel_time_coursecarousel_protocol_time_course
Multiple model, multiple data
joint_steady_statejoint_time_coursejoint_protocol_time_course
Multiple model, multiple data, multiple methods
Here we also allow to run different methods (e.g. steady-state vs time courses) for each combination of model:data.
joint_mixed
Minimizers¶
- LocalScipyMinimizer, including common methods such as Nelder-Mead or L-BFGS-B
- GlobalScipyMinimizer, including common methods such as basin hopping or dual annealing
For this tutorial we are going to use the fit module to optimise our parameter values and the plot module to plot some results.
Let's get started!
Creating synthetic data¶
Normally, you would fit your model to experimental data.
Here, for the sake of simplicity, we will generate some synthetic data.
Checkout the basics tutorial if you need a refresher on building and simulating models.
# As a small trick, let's define a variable for the model function
# That way, we can re-use it all over the file and easily replace
# it with another model
model_fn = get_linear_chain_2v
res = (
Simulator(model_fn())
.update_parameters({"k1": 1.0, "k2": 2.0, "k3": 1.0})
.simulate_time_course(np.linspace(0, 10, 101))
.get_result()
.unwrap_or_err()
).get_combined()
fig, ax = plot.lines(res)
ax.set(xlabel="time / a.u.", ylabel="Conc. & Flux / a.u.")
plt.show()
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Cell In[2], line 8 4 model_fn = get_linear_chain_2v 5 6 res = ( 7 Simulator(model_fn()) ----> 8 .update_parameters({"k1": 1.0, "k2": 2.0, "k3": 1.0}) 9 .simulate_time_course(np.linspace(0, 10, 101)) 10 .get_result() 11 .unwrap_or_err() File ~/work/MxlPy/MxlPy/src/mxlpy/simulator.py:210, in Simulator.update_parameters(self, parameters) 196 def update_parameters(self, parameters: dict[str, float]) -> Self: 197 """Updates the model parameters with the provided dictionary of parameters. 198 199 Examples (...) 208 209 """ --> 210 self.model.update_parameters(parameters) 211 return self File ~/work/MxlPy/MxlPy/src/mxlpy/model.py:861, in Model.update_parameters(self, parameters) 853 self.update_parameter( 854 k, 855 value=v.value, (...) 858 annotations=v.annotations, 859 ) 860 else: --> 861 self.update_parameter(k, v) 862 return self File ~/work/MxlPy/MxlPy/src/mxlpy/model.py:209, in _invalidate_cache.<locals>.wrapper(*args, **kwargs) 207 self = cast(Model, args[0]) 208 self._cache = None --> 209 return method(*args, **kwargs) File ~/work/MxlPy/MxlPy/src/mxlpy/model.py:818, in Model.update_parameter(self, name, value, unit, source, annotations) 816 if name not in self._parameters: 817 msg = f"Parameter {name!r} not found. Available parameters: {sorted(self._parameters)}" --> 818 raise KeyError(msg) 820 parameter = self._parameters[name] 821 if value is not None: KeyError: "Parameter 'k3' not found. Available parameters: ['k1', 'k2', 'k_out']"
# Create data for protocol fitting
protocol = make_protocol(
[
(1, {"k1": 1.0}),
(1, {"k1": 2.0}),
(1, {"k1": 1.0}),
]
)
res_protocol = (
Simulator(model_fn())
.update_parameters({"k1": 1.0, "k2": 2.0, "k3": 1.0})
.simulate_protocol(
protocol,
time_points_per_step=10,
)
.get_result()
.unwrap_or_err()
).get_combined()
fig, ax = plot.lines(res_protocol)
ax.set(xlabel="time / a.u.", ylabel="Conc. & Flux / a.u.")
plt.show()
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Cell In[3], line 12 8 ) 9 10 res_protocol = ( 11 Simulator(model_fn()) ---> 12 .update_parameters({"k1": 1.0, "k2": 2.0, "k3": 1.0}) 13 .simulate_protocol( 14 protocol, 15 time_points_per_step=10, File ~/work/MxlPy/MxlPy/src/mxlpy/simulator.py:210, in Simulator.update_parameters(self, parameters) 196 def update_parameters(self, parameters: dict[str, float]) -> Self: 197 """Updates the model parameters with the provided dictionary of parameters. 198 199 Examples (...) 208 209 """ --> 210 self.model.update_parameters(parameters) 211 return self File ~/work/MxlPy/MxlPy/src/mxlpy/model.py:861, in Model.update_parameters(self, parameters) 853 self.update_parameter( 854 k, 855 value=v.value, (...) 858 annotations=v.annotations, 859 ) 860 else: --> 861 self.update_parameter(k, v) 862 return self File ~/work/MxlPy/MxlPy/src/mxlpy/model.py:209, in _invalidate_cache.<locals>.wrapper(*args, **kwargs) 207 self = cast(Model, args[0]) 208 self._cache = None --> 209 return method(*args, **kwargs) File ~/work/MxlPy/MxlPy/src/mxlpy/model.py:818, in Model.update_parameter(self, name, value, unit, source, annotations) 816 if name not in self._parameters: 817 msg = f"Parameter {name!r} not found. Available parameters: {sorted(self._parameters)}" --> 818 raise KeyError(msg) 820 parameter = self._parameters[name] 821 if value is not None: KeyError: "Parameter 'k3' not found. Available parameters: ['k1', 'k2', 'k_out']"
Steady-states¶
For the steady-state fit we need two inputs:
- the steady state data, which we supply as a
pandas.Series - an initial parameter guess
The fitting routine will compare all data contained in that series to the model output.
Note that the data both contains concentrations and fluxes!
data = res.iloc[-1]
data.head()
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[4], line 1 ----> 1 data = res.iloc[-1] 2 data.head() NameError: name 'res' is not defined
fit_result = fit.steady_state(
model_fn(),
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
data=res.iloc[-1],
minimizer=fit.LocalScipyMinimizer(),
).unwrap_or_err()
fit_result.best_pars
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[5], line 4 1 fit_result = fit.steady_state( 2 model_fn(), 3 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, ----> 4 data=res.iloc[-1], 5 minimizer=fit.LocalScipyMinimizer(), 6 ).unwrap_or_err() 7 NameError: name 'res' is not defined
If only some of the data is required, you can use a subset of it.
The fitting routine will only try to fit concentrations and fluxes contained in that series.
fit_result = fit.steady_state(
model_fn(),
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
data=data.loc[["x", "y"]],
minimizer=fit.LocalScipyMinimizer(),
).unwrap_or_err()
fit_result.best_pars
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[6], line 4 1 fit_result = fit.steady_state( 2 model_fn(), 3 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, ----> 4 data=data.loc[["x", "y"]], 5 minimizer=fit.LocalScipyMinimizer(), 6 ).unwrap_or_err() 7 fit_result.best_pars NameError: name 'data' is not defined
By default, mxlpy will apply standard scaling to all fitting functions.
Specifically, it will calculate loss_fn(data - data.mean()) / data.std(), (pred - data.mean()) / data.std()).
To turn off this behaviour, set standard_scale=False in the fit functions
fit_result = fit.steady_state(
model_fn(),
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
data=data.loc[["x", "y"]],
minimizer=fit.LocalScipyMinimizer(),
standard_scale=False, # opt-out of standard scaling
).unwrap_or_err()
fit_result.best_pars
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[7], line 4 1 fit_result = fit.steady_state( 2 model_fn(), 3 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, ----> 4 data=data.loc[["x", "y"]], 5 minimizer=fit.LocalScipyMinimizer(), 6 standard_scale=False, # opt-out of standard scaling 7 ).unwrap_or_err() NameError: name 'data' is not defined
Time course¶
For the time course fit we need again need two inputs
- the time course data, which we supply as a
pandas.DataFrame - an initial parameter guess
The fitting routine will create data at every time points specified in the DataFrame and compare all of them.
Other than that, the same rules of the steady-state fitting apply.
fit_result = fit.time_course(
model_fn(),
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
data=res,
minimizer=fit.LocalScipyMinimizer(),
).unwrap_or_err()
fit_result.best_pars
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[8], line 4 1 fit_result = fit.time_course( 2 model_fn(), 3 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, ----> 4 data=res, 5 minimizer=fit.LocalScipyMinimizer(), 6 ).unwrap_or_err() 7 NameError: name 'res' is not defined
Protocol time courses¶
For the protocol time course fit we need three inputs
- an initial parameter guess
- the time course data, which we supply as a
pandas.DataFrame - the protocol, which we supply as a
pandas.DataFrame
Note that the parameter given by the protocol cannot be fitted anymore
You can use the make_protocol function to create a protocol (see above).
The protocol DataFrame should preferrably use a pd.TimedeltaIndex and is interpreted as "use the parameter values of that row until the given end point."
Here a second corresponds to a unit of simulation time, regardless of model time scale.
mxlpy will attempt to convert other indices, again assuming that a second in your data corresponds to a second of simulation time.
protocol
| k1 | |
|---|---|
| Timedelta | |
| 0 days 00:00:01 | 1.0 |
| 0 days 00:00:02 | 2.0 |
| 0 days 00:00:03 | 1.0 |
fit_result = fit.protocol_time_course(
model_fn(),
p0={"k2": 1.87, "k3": 1.093}, # note that k1 is given by the protocol
data=res_protocol,
protocol=protocol,
minimizer=fit.LocalScipyMinimizer(),
).unwrap_or_err()
fit_result.best_pars
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[10], line 4 1 fit_result = fit.protocol_time_course( 2 model_fn(), 3 p0={"k2": 1.87, "k3": 1.093}, # note that k1 is given by the protocol ----> 4 data=res_protocol, 5 protocol=protocol, 6 minimizer=fit.LocalScipyMinimizer(), 7 ).unwrap_or_err() NameError: name 'res_protocol' is not defined
Group fitting (multi-start optimisation)¶
mxlpy supports group fitting, which is a single-model, single-data approach where the same model is fitted to the same data from many different initial parameter guesses.
This is exactly what is commonly called multi-start (or multistart) optimisation: each row of the p0 DataFrame is one start, the starts are run in parallel, and a GroupFit is returned. Use get_best_fit() to retrieve the best result and get_losses() to inspect the loss of every start.
A convenient way to generate diverse start guesses is
mxlpy.distributions.sample, as shown in the monte-carlo combination further down.
group_fit = fit.group_steady_state(
model_fn(),
data=res.iloc[-1],
p0=pd.DataFrame(
{
"k1": [1.037, 1.038, 1.039],
"k2": [1.86, 1.87, 1.88],
"k3": [1.092, 1.093, 1.094],
}
),
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[11], line 3 1 group_fit = fit.group_steady_state( 2 model_fn(), ----> 3 data=res.iloc[-1], 4 p0=pd.DataFrame( 5 { 6 "k1": [1.037, 1.038, 1.039], NameError: name 'res' is not defined
Time course¶
Time course fits are adjusted just the same
group_fit = fit.group_time_course(
model_fn(),
data=res,
p0=pd.DataFrame(
{
"k1": [1.037, 1.038, 1.039],
"k2": [1.86, 1.87, 1.88],
"k3": [1.092, 1.093, 1.094],
}
),
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[12], line 3 1 group_fit = fit.group_time_course( 2 model_fn(), ----> 3 data=res, 4 p0=pd.DataFrame( 5 { 6 "k1": [1.037, 1.038, 1.039], NameError: name 'res' is not defined
Protocol time course¶
As are protocol time courses
group_fit = fit.group_protocol_time_course(
model_fn(),
data=res_protocol,
protocol=protocol,
p0=pd.DataFrame(
{
"k1": [1.037, 1.038, 1.039],
"k2": [1.86, 1.87, 1.88],
"k3": [1.092, 1.093, 1.094],
}
),
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[13], line 3 1 group_fit = fit.group_protocol_time_course( 2 model_fn(), ----> 3 data=res_protocol, 4 protocol=protocol, 5 p0=pd.DataFrame( 6 { NameError: name 'res_protocol' is not defined
Combining with monte-carlo approaches¶
An especially useful combination is combining group fitting with the monte-carlo capabilities of mxlpy to quickly get multiple fits from randomly selected initial conditions
from mxlpy.distributions import Uniform, sample
group_fit = fit.group_steady_state(
model_fn(),
data=res.iloc[-1],
p0=sample(
{
"k1": Uniform(1.037, 1.039),
"k2": Uniform(1.86, 1.88),
"k3": Uniform(1.092, 1.094),
},
n=3,
),
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[14], line 5 1 from mxlpy.distributions import Uniform, sample 2 3 group_fit = fit.group_steady_state( 4 model_fn(), ----> 5 data=res.iloc[-1], 6 p0=sample( 7 { 8 "k1": Uniform(1.037, 1.039), NameError: name 'res' is not defined
group_fit.get_losses()
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[15], line 1 ----> 1 group_fit.get_losses() NameError: name 'group_fit' is not defined
best_model = group_fit.get_best_fit().model
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[16], line 1 ----> 1 best_model = group_fit.get_best_fit().model NameError: name 'group_fit' is not defined
Ensemble fitting¶
mxlpy supports ensemble fitting, which is a multi-model single data approach, where shared parameters will be applied to all models at the same time.
Here you supply an iterable of models instead of just one, otherwise the API stays the same.
ensemble_fit = fit.ensemble_steady_state(
[
model_fn(),
model_fn(),
],
data=res.iloc[-1],
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[17], line 6 2 [ 3 model_fn(), 4 model_fn(), 5 ], ----> 6 data=res.iloc[-1], 7 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, 8 minimizer=fit.LocalScipyMinimizer(tol=1e-6), 9 ) NameError: name 'res' is not defined
To get the best fitting model, you can use get_best_fit on the ensemble fit
fit_result = ensemble_fit.get_best_fit()
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[18], line 1 ----> 1 fit_result = ensemble_fit.get_best_fit() NameError: name 'ensemble_fit' is not defined
And you can of course also access all other fits
[i.loss for i in ensemble_fit.fits]
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[19], line 1 ----> 1 [i.loss for i in ensemble_fit.fits] NameError: name 'ensemble_fit' is not defined
Time course¶
Time course fits are adjusted just the same
ensemble_fit = fit.ensemble_time_course(
[
model_fn(),
model_fn(),
],
data=res,
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[20], line 6 2 [ 3 model_fn(), 4 model_fn(), 5 ], ----> 6 data=res, 7 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, 8 minimizer=fit.LocalScipyMinimizer(tol=1e-6), 9 ) NameError: name 'res' is not defined
Protocol time course¶
As are protocol time courses
ensemble_fit = fit.ensemble_protocol_time_course(
[
model_fn(),
model_fn(),
],
data=res_protocol,
protocol=protocol,
p0={"k2": 1.87, "k3": 1.093}, # note that k1 is given by the protocol
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[21], line 6 2 [ 3 model_fn(), 4 model_fn(), 5 ], ----> 6 data=res_protocol, 7 protocol=protocol, 8 p0={"k2": 1.87, "k3": 1.093}, # note that k1 is given by the protocol 9 minimizer=fit.LocalScipyMinimizer(tol=1e-6), NameError: name 'res_protocol' is not defined
Joint fitting¶
Next, we support joint fitting, which is a combined multi-model multi-data approach, where shared parameters will be applied to all models at the same time
fit.joint_steady_state(
[
fit.FitSettings(model=model_fn(), data=res.iloc[-1]),
fit.FitSettings(model=model_fn(), data=res.iloc[-1]),
],
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[22], line 3 1 fit.joint_steady_state( 2 [ ----> 3 fit.FitSettings(model=model_fn(), data=res.iloc[-1]), 4 fit.FitSettings(model=model_fn(), data=res.iloc[-1]), 5 ], 6 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, NameError: name 'res' is not defined
fit.joint_time_course(
[
fit.FitSettings(model=model_fn(), data=res),
fit.FitSettings(model=model_fn(), data=res),
],
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[23], line 3 1 fit.joint_time_course( 2 [ ----> 3 fit.FitSettings(model=model_fn(), data=res), 4 fit.FitSettings(model=model_fn(), data=res), 5 ], 6 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, NameError: name 'res' is not defined
fit.joint_protocol_time_course(
[
fit.FitSettings(model=model_fn(), data=res_protocol, protocol=protocol),
fit.FitSettings(model=model_fn(), data=res_protocol, protocol=protocol),
],
p0={"k2": 1.87, "k3": 1.093},
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[24], line 3 1 fit.joint_protocol_time_course( 2 [ ----> 3 fit.FitSettings(model=model_fn(), data=res_protocol, protocol=protocol), 4 fit.FitSettings(model=model_fn(), data=res_protocol, protocol=protocol), 5 ], 6 p0={"k2": 1.87, "k3": 1.093}, NameError: name 'res_protocol' is not defined
Mixed joint fitting¶
Lastly, we support mixed-joint fitting, where each analysis takes it's own residual function to allow fitting both time series and steady-state data for multiple models at the same time.
fit.joint_mixed(
[
fit.MixedSettings(
model=model_fn(),
data=res.iloc[-1],
residual_fn=fit.steady_state_residual,
),
fit.MixedSettings(
model=model_fn(),
data=res,
residual_fn=fit.time_course_residual,
),
fit.MixedSettings(
model=model_fn(),
data=res_protocol,
protocol=protocol,
residual_fn=fit.protocol_time_course_residual,
),
],
p0={"k2": 1.87, "k3": 1.093},
minimizer=fit.LocalScipyMinimizer(tol=1e-6),
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[25], line 5 1 fit.joint_mixed( 2 [ 3 fit.MixedSettings( 4 model=model_fn(), ----> 5 data=res.iloc[-1], 6 residual_fn=fit.steady_state_residual, 7 ), 8 fit.MixedSettings( NameError: name 'res' is not defined
First finish line
With that you now know most of what you will need from a day-to-day basis about fitting in mxlpy.Congratulations!
Advanced topics / customisation¶
All fitting routines internally are build in a way that they will call a tree of functions.
minimizerresidual_fnintegratorloss_fn
You can therefore use dependency injection to overwrite the minimisation function, the loss function, the residual function and the integrator if need be.
from functools import partial
from typing import cast
from mxlpy.integrators import Scipy
Parameterising scipy optimise¶
optimizer = fit.LocalScipyMinimizer(tol=1e-6, method="Nelder-Mead")
Custom loss function¶
You can change the loss function that is being passed to the minimsation function using the loss_fn keyword.
Depending on the use case (time course vs steady state) this function will be passed two pandas DataFrames or Series.
def mean_absolute_error(
x: pd.DataFrame | pd.Series,
y: pd.DataFrame | pd.Series,
) -> float:
"""Mean absolute error between two dataframes."""
return cast(float, np.mean(np.abs(x - y)))
(
fit.time_course(
model_fn(),
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
data=res,
loss_fn=mean_absolute_error,
minimizer=fit.LocalScipyMinimizer(),
)
.unwrap_or_err()
.best_pars
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[28], line 13 9 ( 10 fit.time_course( 11 model_fn(), 12 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, ---> 13 data=res, 14 loss_fn=mean_absolute_error, 15 minimizer=fit.LocalScipyMinimizer(), 16 ) NameError: name 'res' is not defined
Custom integrator¶
You can change the default integrator to an integrator of your choice by partially application of the class of any of the existing ones.
Here, for example, we choose the Scipy solver suite and set the default relative and absolute tolerances to 1e-6 respectively.
(
fit.time_course(
model_fn(),
p0={"k1": 1.038, "k2": 1.87, "k3": 1.093},
data=res,
integrator=partial(Scipy, rtol=1e-6, atol=1e-6),
minimizer=fit.LocalScipyMinimizer(),
)
.unwrap_or_err()
.best_pars
)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[29], line 5 1 ( 2 fit.time_course( 3 model_fn(), 4 p0={"k1": 1.038, "k2": 1.87, "k3": 1.093}, ----> 5 data=res, 6 integrator=partial(Scipy, rtol=1e-6, atol=1e-6), 7 minimizer=fit.LocalScipyMinimizer(), 8 ) NameError: name 'res' is not defined