from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import mxlpy as mb2
from example_models import (
get_lin_chain_two_circles,
get_linear_chain_2v,
get_upper_glycolysis,
)
from mxlpy import make_protocol, mc, mca, plot
Monte Carlo methods¶
Almost every parameter in biology is better described with a distribution than a single value.
Monte-carlo methods allow you to capture the range of possible behaviour your model can exhibit.
This is especially useful when you want to understand the uncertainty in your model's predictions.
mxlpy offers these Monte Carlo methods for all scans ...
 +
+
 =
=
and even for metabolic control analysis
 +
=
+
=
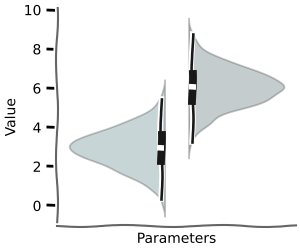
In this tutorial we will mostly use the mxlpy.distributions and mxlpy.mca modules, which contain the functionality to sample from distributions and run distributed analyses.
Sample values¶
To do any Monte-Carlo analysis, we first need to be able to sample values.
For that, you can use the sample function and distributions supplied by mxlpy.
These are mostly thin wrappers around the numpy and scipy sampling methods.
from mxlpy.distributions import LogNormal, Uniform, sample
sample(
{
"k2": Uniform(1.0, 2.0),
"k3": LogNormal(mean=1.0, sigma=1.0),
},
n=5,
)
| k2 | k3 | |
|---|---|---|
| 0 | 1.773956 | 0.739205 |
| 1 | 1.438878 | 3.088978 |
| 2 | 1.858598 | 1.981308 |
| 3 | 1.697368 | 2.672993 |
| 4 | 1.094177 | 1.158303 |
Steady-state¶
Using mc.steady_state you can calculate the steady-state distribution given the monte-carlo parameters.
This works analogously to the scan.steady_state function, except the index of the dataframes is always just an integer.
The parameters used can be obtained by result.parameters.
We will use a linear chain of reactions with two circles as an example model for this notebook.
$$ \begin{array}{c|c} \mathrm{Reaction} & \mathrm{Stoichiometry} \\ \hline v_0 & \varnothing \rightarrow{} \mathrm{x_1} \\ v_1 & -\mathrm{x_1} \rightarrow{} \mathrm{x_2} \\ v_2 & -\mathrm{x_1} \rightarrow{} \mathrm{x_3} \\ v_3 & -\mathrm{x_1} \rightarrow{} \mathrm{x_4} \\ v_4 & -\mathrm{x_4} \rightarrow{} \varnothing\\ v_5 & -\mathrm{x_2} \rightarrow{} \mathrm{x_1} \\ v_6 & -\mathrm{x_3} \rightarrow{} \mathrm{x_1} \\ \end{array} $$
ss = mc.steady_state(
get_linear_chain_2v(),
mc_to_scan=sample(
{
"k1": Uniform(0.9, 1.1),
"k2": Uniform(1.0, 1.3),
"k3": LogNormal(mean=1.0, sigma=0.2),
},
n=10,
),
)
fig, (ax1, ax2) = plot.two_axes(figsize=(6, 2.5), sharex=False)
plot.violins(ss.variables, ax=ax1)
plot.violins(ss.fluxes, ax=ax2)
ax1.set(xlabel="Variables", ylabel="Concentration / a.u.")
ax2.set(xlabel="Reactions", ylabel="Flux / a.u.")
plt.show()
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:05<00:49, 5.55s/it]
50%|█████ | 5/10 [00:05<00:04, 1.16it/s]
100%|██████████| 10/10 [00:05<00:00, 1.74it/s]

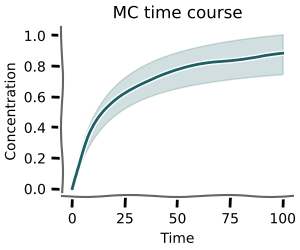
Time course¶
Using mc.time_course you can calculate time courses for sampled parameters.
+
=
This function works analogously to scan.time_course.
The pandas.DataFrames for concentrations and fluxes have a n x time pandas.MultiIndex.
The corresponding parameters can be found in result.parameters
tc = mc.time_course(
get_linear_chain_2v(),
time_points=np.linspace(0, 1, 11),
mc_to_scan=sample(
{
"k1": Uniform(0.9, 1.1),
"k2": Uniform(1.0, 1.3),
"k3": LogNormal(mean=1.0, sigma=0.2),
},
n=10,
),
)
fig, (ax1, ax2) = plot.two_axes(figsize=(7, 4))
plot.lines_mean_std_from_2d_idx(tc.variables, ax=ax1)
plot.lines_mean_std_from_2d_idx(tc.fluxes, ax=ax2)
ax1.set(xlabel="Time / a.u", ylabel="Concentration / a.u.")
ax2.set(xlabel="Time / a.u", ylabel="Flux / a.u.")
plt.show()
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:05<00:50, 5.60s/it]
50%|█████ | 5/10 [00:05<00:04, 1.16it/s]
100%|██████████| 10/10 [00:05<00:00, 1.74it/s]

Protocol time course¶
Using mc.time_course_over_protocol you can calculate time courses for sampled parameters given a discrete protocol.
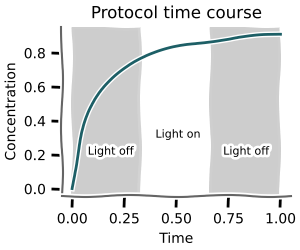 +
=
+
=
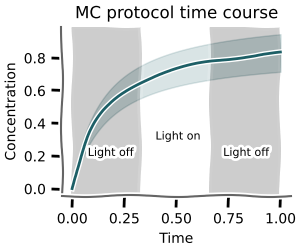
The pandas.DataFrames for concentrations and fluxes have a n x time pandas.MultiIndex.
The corresponding parameters can be found in scan.parameters
tc = mc.protocol_time_course(
get_linear_chain_2v(),
time_points=np.linspace(0, 6, 21),
protocol=make_protocol(
[
(1, {"k1": 1}),
(2, {"k1": 2}),
(3, {"k1": 1}),
]
),
mc_to_scan=sample(
{
"k2": Uniform(1.0, 1.3),
"k3": LogNormal(mean=1.0, sigma=0.2),
},
n=10,
),
)
fig, (ax1, ax2) = plot.two_axes(figsize=(7, 4))
plot.lines_mean_std_from_2d_idx(tc.variables, ax=ax1)
plot.lines_mean_std_from_2d_idx(tc.fluxes, ax=ax2)
for ax in (ax1, ax2):
plot.shade_protocol(tc.protocol["k1"], ax=ax, alpha=0.1)
ax1.set(xlabel="Time / a.u", ylabel="Concentration / a.u.")
ax2.set(xlabel="Time / a.u", ylabel="Flux / a.u.")
plt.show()
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:05<00:49, 5.49s/it]
20%|██ | 2/10 [00:05<00:19, 2.43s/it]
100%|██████████| 10/10 [00:05<00:00, 1.73it/s]

Metabolic control analysis¶
mxlpy further has routines for monte-carlo distributed metabolic control analysis.
This allows quantifying, whether the coefficients obtained from the MCA analysis are robust against parameter changes or whether they are just an artifact of a particular choice of parameters.
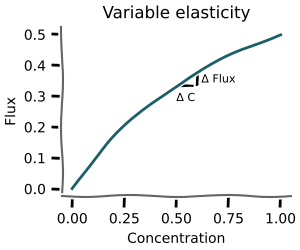
mc_elas = mc.variable_elasticities(
get_upper_glycolysis(),
variables={
"GLC": 0.3,
"G6P": 0.4,
"F6P": 0.5,
"FBP": 0.6,
"ATP": 0.4,
"ADP": 0.6,
},
to_scan=["GLC", "F6P"],
mc_to_scan=sample(
{
# "k1": LogNormal(mean=np.log(0.25), sigma=1.0),
# "k2": LogNormal(mean=np.log(1.0), sigma=1.0),
"k3": LogNormal(mean=np.log(1.0), sigma=1.0),
# "k4": LogNormal(mean=np.log(1.0), sigma=1.0),
# "k5": LogNormal(mean=np.log(1.0), sigma=1.0),
# "k6": LogNormal(mean=np.log(1.0), sigma=1.0),
# "k7": LogNormal(mean=np.log(2.5), sigma=1.0),
},
n=5,
),
)
_ = plot.violins_from_2d_idx(mc_elas)
plt.show()
0%| | 0/5 [00:00<?, ?it/s]
20%|██ | 1/5 [00:05<00:22, 5.58s/it]
40%|████ | 2/5 [00:05<00:07, 2.38s/it]
100%|██████████| 5/5 [00:05<00:00, 1.16s/it]

Parameter elasticities¶
+
=
elas = mc.parameter_elasticities(
get_upper_glycolysis(),
variables={
"GLC": 0.3,
"G6P": 0.4,
"F6P": 0.5,
"FBP": 0.6,
"ATP": 0.4,
"ADP": 0.6,
},
to_scan=["k1", "k2", "k3"],
mc_to_scan=sample(
{
"k3": LogNormal(mean=np.log(0.25), sigma=1.0),
},
n=5,
),
)
_ = plot.violins_from_2d_idx(elas)
plt.show()
0%| | 0/5 [00:00<?, ?it/s]
20%|██ | 1/5 [00:05<00:23, 5.91s/it]
100%|██████████| 5/5 [00:05<00:00, 1.18s/it]

Response coefficients¶
 +
=
+
=
# Compare with "normal" control coefficients
rc = mca.response_coefficients(
get_lin_chain_two_circles(),
to_scan=["vmax_1", "vmax_2", "vmax_3", "vmax_5", "vmax_6"],
)
_ = plot.heatmap(rc.variables)
mrc = mc.response_coefficients(
get_lin_chain_two_circles(),
to_scan=["vmax_1", "vmax_2", "vmax_3", "vmax_5", "vmax_6"],
mc_to_scan=sample(
{
"k0": LogNormal(np.log(1.0), 1.0),
"k4": LogNormal(np.log(0.5), 1.0),
},
n=10,
),
)
_ = plot.violins_from_2d_idx(mrc.variables, n_cols=len(mrc.variables.columns))
0%| | 0/5 [00:00<?, ?it/s]
20%|██ | 1/5 [00:05<00:22, 5.53s/it]
40%|████ | 2/5 [00:05<00:07, 2.42s/it]
100%|██████████| 5/5 [00:05<00:00, 1.16s/it]
0%| | 0/10 [00:00<?, ?it/s]
0%| | 0/5 [00:00<?, ?it/s] 0%| | 0/5 [00:00<?, ?it/s] 0%| | 0/5 [00:00<?, ?it/s] 0%| | 0/5 [00:00<?, ?it/s] 20%|██ | 1/5 [00:00<00:00, 9.43it/s] 40%|████ | 2/5 [00:00<00:00, 11.20it/s]
40%|████ | 2/5 [00:00<00:00, 11.35it/s] 80%|████████ | 4/5 [00:00<00:00, 11.38it/s] 80%|████████ | 4/5 [00:00<00:00, 11.99it/s] 60%|██████ | 3/5 [00:00<00:00, 9.96it/s]
100%|██████████| 5/5 [00:00<00:00, 11.93it/s] 100%|██████████| 5/5 [00:00<00:00, 11.35it/s] 10%|█ | 1/10 [00:06<00:54, 6.10s/it]
100%|██████████| 5/5 [00:00<00:00, 10.69it/s] 100%|██████████| 5/5 [00:00<00:00, 10.47it/s] 20%|██ | 2/10 [00:06<00:20, 2.58s/it]
0%| | 0/5 [00:00<?, ?it/s] 0%| | 0/5 [00:00<?, ?it/s]
0%| | 0/5 [00:00<?, ?it/s] 40%|████ | 2/5 [00:00<00:00, 13.63it/s]
40%|████ | 2/5 [00:00<00:00, 10.19it/s]
80%|████████ | 4/5 [00:00<00:00, 12.03it/s] 100%|██████████| 5/5 [00:00<00:00, 11.96it/s] 0%| | 0/5 [00:00<?, ?it/s] 80%|████████ | 4/5 [00:00<00:00, 10.18it/s]
40%|████ | 2/5 [00:00<00:00, 12.34it/s] 100%|██████████| 5/5 [00:00<00:00, 10.13it/s] 0%| | 0/5 [00:00<?, ?it/s] 80%|████████ | 4/5 [00:00<00:00, 12.26it/s]
40%|████ | 2/5 [00:00<00:00, 10.68it/s] 100%|██████████| 5/5 [00:00<00:00, 12.20it/s] 0%| | 0/5 [00:00<?, ?it/s] 80%|████████ | 4/5 [00:00<00:00, 10.69it/s]
40%|████ | 2/5 [00:00<00:00, 11.96it/s] 100%|██████████| 5/5 [00:00<00:00, 10.65it/s] 80%|████████ | 4/5 [00:00<00:00, 13.99it/s] 100%|██████████| 5/5 [00:00<00:00, 14.73it/s]
20%|██ | 1/5 [00:04<00:17, 4.41s/it]
20%|██ | 1/5 [00:04<00:16, 4.18s/it]
40%|████ | 2/5 [00:07<00:11, 3.87s/it]
40%|████ | 2/5 [00:07<00:11, 3.83s/it]
60%|██████ | 3/5 [00:11<00:07, 3.71s/it]
60%|██████ | 3/5 [00:11<00:07, 3.72s/it]
80%|████████ | 4/5 [00:15<00:03, 3.70s/it]
80%|████████ | 4/5 [00:14<00:03, 3.66s/it]
100%|██████████| 5/5 [00:18<00:00, 3.63s/it] 100%|██████████| 5/5 [00:18<00:00, 3.72s/it] 40%|████ | 4/10 [00:24<00:39, 6.62s/it]
100%|██████████| 5/5 [00:18<00:00, 3.62s/it] 100%|██████████| 5/5 [00:18<00:00, 3.69s/it] 60%|██████ | 6/10 [00:24<00:14, 3.62s/it]
100%|██████████| 10/10 [00:24<00:00, 2.48s/it]


First finish line
With that you now know most of what you will need from a day-to-day basis about monte carlo methods in mxlpy.Congratulations!
Advanced topics¶
Parameter scans¶
Vary both monte carlo parameters as well as systematically scan for other parameters
mcss = mc.scan_steady_state(
get_linear_chain_2v(),
to_scan=pd.DataFrame({"k1": np.linspace(0, 1, 3)}),
mc_to_scan=sample(
{
"k2": Uniform(1.0, 1.3),
"k3": LogNormal(mean=1.0, sigma=0.2),
},
n=10,
),
)
plot.violins_from_2d_idx(mcss.variables)
plt.show()
0%| | 0/10 [00:00<?, ?it/s]
0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 103.43it/s] 0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 144.17it/s]
0%| | 0/3 [00:00<?, ?it/s] 0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 115.85it/s] 10%|█ | 1/10 [00:05<00:49, 5.48s/it]
100%|██████████| 3/3 [00:00<00:00, 189.09it/s]
0%| | 0/3 [00:00<?, ?it/s] 0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 100.18it/s] 0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 140.77it/s] 100%|██████████| 3/3 [00:00<00:00, 88.56it/s] 0%| | 0/3 [00:00<?, ?it/s] 0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 100.63it/s] 0%| | 0/3 [00:00<?, ?it/s] 100%|██████████| 3/3 [00:00<00:00, 172.27it/s] 100%|██████████| 3/3 [00:00<00:00, 113.59it/s] 40%|████ | 4/10 [00:05<00:06, 1.11s/it]
100%|██████████| 10/10 [00:05<00:00, 1.73it/s]
INFO:matplotlib.category:Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.
INFO:matplotlib.category:Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.
INFO:matplotlib.category:Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.
INFO:matplotlib.category:Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.

# FIXME: no idea how to plot this yet. Ridge plots?
# Maybe it's just a bit much :D
mcss = mc.scan_steady_state(
get_linear_chain_2v(),
to_scan=mb2.cartesian_product(
{
"k1": np.linspace(0, 1, 3),
"k2": np.linspace(0, 1, 3),
}
),
mc_to_scan=sample(
{
"k3": LogNormal(mean=1.0, sigma=0.2),
},
n=10,
),
)
mcss.variables.head()
0%| | 0/10 [00:00<?, ?it/s]
0%| | 0/9 [00:00<?, ?it/s] 0%| | 0/9 [00:00<?, ?it/s] 0%| | 0/9 [00:00<?, ?it/s] 0%| | 0/9 [00:00<?, ?it/s]
44%|████▍ | 4/9 [00:00<00:01, 4.89it/s] 44%|████▍ | 4/9 [00:00<00:01, 4.93it/s] 44%|████▍ | 4/9 [00:00<00:01, 4.93it/s] 44%|████▍ | 4/9 [00:00<00:01, 4.94it/s]
78%|███████▊ | 7/9 [00:01<00:00, 4.22it/s] 100%|██████████| 9/9 [00:01<00:00, 5.52it/s] 10%|█ | 1/10 [00:06<01:02, 6.89s/it] 78%|███████▊ | 7/9 [00:01<00:00, 4.27it/s]
100%|██████████| 9/9 [00:01<00:00, 5.59it/s] 78%|███████▊ | 7/9 [00:01<00:00, 4.28it/s] 100%|██████████| 9/9 [00:01<00:00, 5.60it/s] 78%|███████▊ | 7/9 [00:01<00:00, 4.36it/s] 100%|██████████| 9/9 [00:01<00:00, 5.70it/s] 30%|███ | 3/10 [00:07<00:12, 1.83s/it]
0%| | 0/9 [00:00<?, ?it/s]
0%| | 0/9 [00:00<?, ?it/s] 0%| | 0/9 [00:00<?, ?it/s] 0%| | 0/9 [00:00<?, ?it/s]
44%|████▍ | 4/9 [00:00<00:00, 5.17it/s] 44%|████▍ | 4/9 [00:00<00:00, 5.05it/s] 44%|████▍ | 4/9 [00:00<00:00, 5.01it/s] 44%|████▍ | 4/9 [00:00<00:00, 5.04it/s]
78%|███████▊ | 7/9 [00:01<00:00, 4.38it/s] 100%|██████████| 9/9 [00:01<00:00, 5.75it/s] 0%| | 0/9 [00:00<?, ?it/s] 50%|█████ | 5/10 [00:08<00:06, 1.32s/it]
78%|███████▊ | 7/9 [00:01<00:00, 4.33it/s] 100%|██████████| 9/9 [00:01<00:00, 5.67it/s] 0%| | 0/9 [00:00<?, ?it/s] 78%|███████▊ | 7/9 [00:01<00:00, 4.31it/s] 100%|██████████| 9/9 [00:01<00:00, 5.64it/s] 78%|███████▊ | 7/9 [00:01<00:00, 4.33it/s] 100%|██████████| 9/9 [00:01<00:00, 5.68it/s] 80%|████████ | 8/10 [00:08<00:01, 1.55it/s]
44%|████▍ | 4/9 [00:00<00:00, 9.18it/s] 44%|████▍ | 4/9 [00:00<00:00, 8.32it/s]
78%|███████▊ | 7/9 [00:00<00:00, 8.06it/s] 100%|██████████| 9/9 [00:00<00:00, 10.53it/s] 78%|███████▊ | 7/9 [00:00<00:00, 7.73it/s] 100%|██████████| 9/9 [00:00<00:00, 10.01it/s] 100%|██████████| 10/10 [00:09<00:00, 1.78it/s]
100%|██████████| 10/10 [00:09<00:00, 1.05it/s]
| x | y | |||
|---|---|---|---|---|
| k1 | k2 | |||
| 0 | 0.0 | 0.0 | 1.000000e+00 | -9.723541e-20 |
| 0.5 | 5.981356e-20 | 5.981341e-20 | ||
| 1.0 | -1.714232e-23 | -6.924224e-22 | ||
| 0.5 | 0.0 | NaN | NaN | |
| 0.5 | 1.000000e+00 | 5.000000e-01 |
Custom distributions¶
If you want to create custom distributions, all you need to do is to create a class that follows the Distribution protocol, e.g. implements a sample function.
For API consistency, the sample method has to take rng argument, which can be ignored if not applicable.
from dataclasses import dataclass
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from mxlpy.types import Array
@dataclass
class MyOwnDistribution:
loc: float = 0.0
scale: float = 1.0
def sample(
self,
num: int,
rng: np.random.Generator | None = None,
) -> Array:
if rng is None:
rng = np.random.default_rng()
return rng.normal(loc=self.loc, scale=self.scale, size=num)
sample({"p1": MyOwnDistribution()}, n=5)
| p1 | |
|---|---|
| 0 | -0.953559 |
| 1 | 0.279974 |
| 2 | -1.723190 |
| 3 | -0.135985 |
| 4 | -1.678864 |